How to sort by title
· One min read
Analyzer
- Char Mapping
- remove special chars by regex [^a-zA-Z0-9]
- lowercase
Index
- fielddata=true
Char Mapping
Ä -> a
Ü -> u
Ö -> o
ä -> a
ü -> u
ö -> o
ß -> ss
Analyzer
Index
Ä -> a
Ü -> u
Ö -> o
ä -> a
ü -> u
ö -> o
ß -> ss
For each product the account id and the last order date for this product is sent in an array.
{
"sku" : "",
"accountIdsSort": [
{
"accountId": "001O0Q0001vkeX7QXX",
"lastOrderDate": "2021-10-04T06:11:13Z"
},
{
"accountId": "00I0OQQQ01vkiX5ZXX",
"lastOrderDate": "2021-09-04T06:33:25Z"
}
]
}
In the index we serialize every entry to a string.
{
"accountIdsSort": [
"{accountId=001O0Q0001vkeX7QXX, lastOrderDate=2021-10-04T06:11:13Z}",
"{accountId=00I0OQQQ01vkiX5ZXX, lastOrderDate=2021-09-04T06:33:25Z}"
]
}
To sort the entries a sort _script is used.
The script filter all entries from the array with the prefix of the account id {accountId=001O0Q0001vkeX7QXX
And return the first matching entry.
Elastic is using this for the sorting.
[
{
"_script": {
"script": {
"source": "return doc['accountIdsSort'].stream().filter(x -> x.startsWith('{accountId=' + params.accountId)).findFirst().orElse('a');",
"params": {
"accountId": "$query.f.accountIds"
}
},
"type": "string",
"order": "desc"
}
}
]
Advantages:
Disadvantages:
Because of the bad performance and timeouts another approach with hashed long values was implemented.
[
{
"_script": {
"script": {
"source": "return doc['accountIdsSortHashes'].stream().filter(x -> x > params.accountIdHash && x < params.accountIdHash + 1000000000).findFirst().orElse(0);",
"params": {
"accountIdHash": "$accountIdHash"
}
},
"type": "number",
"order": "desc"
}
}
]
Advantages:
Disadvantages:
public static long hashToLong(String input) throws NoSuchAlgorithmException {
MessageDigest digest = MessageDigest.getInstance("SHA-256");
byte[] hashBytes = digest.digest(input.getBytes());
long value = new BigInteger(1, hashBytes).longValue();
return Math.abs(value % 1000000000000000000L) / 100000000;
}
Long accountIdHash = hashToLong(accountIdDTO.getAccountId());
ZonedDateTime zonedDateTime = ZonedDateTime.parse(accountIdDTO.getLastOrderDate(), DateTimeFormatter.ISO_DATE_TIME);
Instant instant = zonedDateTime.toInstant();
long finalHash = accountIdHash * 1000000000 + instant.toEpochMilli() / 10000;
generation -> gen
tokenizer: standard char_filter: mapping filter:
Token filter [delimiter_search_index] cannot be used to parse synonyms
https://qsc.quasiris.de/api/v1/search/suggest2/ab/products?q=wago - deprected - used by AB
https://qsc.quasiris.de/api/v1/search/suggest/ab/products?q=wago - deprecated - used by shopware plugin
https://qsc-dev.quasiris.de/api/v1/suggest/wins/suggest?q=iphone - secured by token
https://qsc-dev.quasiris.de/api/v1/suggest/ab/products?q=w - secured by token
a suggest can have multiple results
keywords
products
categories
advantage
disadvantage
whent to use
Eine Suchergebnisseite setzt sich aus mehreren Kompontenen zusammen.
Der Nutzer hat mit diesen Komponenten die Möglichkeit das Suchergebnis weiter zu verfeinern.
In der Folgenden Tabelle sind in der ersten Spalte die Aktionen aufgelistet, mit denen der Nutzer mit der Suchergebnisseite interagieren kann. Die weiteren Spalten behinhalten die Komponenten mit ihrem jeweiligen Verhalten bei einer ausgeführten Aktion
| action | documents | filter | pagination | sorting | search box |
|---|---|---|---|---|---|
| select filter | reload | keep other filters | reset | - | - |
| remove filter | reload | keep other filters | reset | - | - |
| use slider | reload | keep other filters | reset | - | - |
| change sorting | reload | - | reset | change | - |
| type in suggest box | - | - | - | - | show suggest |
| submit a search | reload | reset | reset | - | hide suggest |
| click on document | - | - | - | - | - |
In this blog post i will show our best practice how to upgrade elasticsearch.
There are different ways to upgrad elatic:
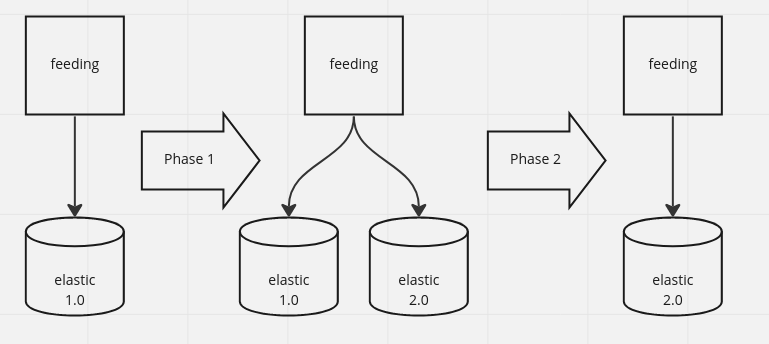
Phase 1
Phase 2
Advantages
Disadvantages
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"filter": [
"my_word_delimiter_filter",
"lowercase",
"my_synonym_filter"
]
}
},
"filter": {
"my_word_delimiter_filter": {
"type": "word_delimiter_graph",
"generate_word_parts": true,
"catenate_words": false
},
"my_synonym_filter": {
"type": "synonym",
"synonyms_path": "analysis/synonyms.txt"
}
}
}
}
}
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Token filter [my_word_delimiter_filter] cannot be used to parse synonyms"
}
],
"type": "illegal_argument_exception",
"reason": "Token filter [my_word_delimiter_filter] cannot be used to parse synonyms"
},
"status": 400
}

{
"filter": [
"my_synonym_filter",
"my_word_delimiter_filter",
"lowercase"
]
}
Problem:
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"filter": [
"my_word_delimiter_filter",
"lowercase",
"my_synonym_filter"
]
}
},
"filter": {
"my_multiplexer": {
"type": "multiplexer",
"filters": [ "delimiter_search_index, lowercase",
"lowercase, Synonym Graph, query_stopwords, stem_override, Snowball, unique"
]
},
"my_word_delimiter_filter": {
"type": "word_delimiter_graph",
"generate_word_parts": true,
"catenate_words": false
},
"my_synonym_filter": {
"type": "synonym",
"synonyms_path": "analysis/synonyms.txt"
}
}
}
}
}
Prices in ecommerce are a complex topic. In B2B scenarios you can have a different price for each customer for one product. The price can also depend of the purchased quantity (Staffelpreise).
{
"title" : "iphone x",
"price_customer_1": 499.0,
"price_customer_2": 599.0,
"price_customer_n": 699.0
}
If the prices are stable and there are not that much variants (max. 100) per product, than the simple approach is a good choice.
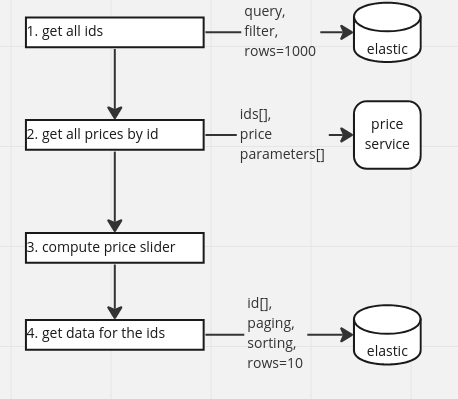
add the slider to the response