Facet generation
Introduction
Faceted Search
A comfortable way of searching through data is by using facets. Using a faceted search makes it possible to filter all kinds of properties. To supply meaningful facets to users by hand is a lot of work, especially in scenarios with tens of thousands of searchable items.
Finding meaningful facets
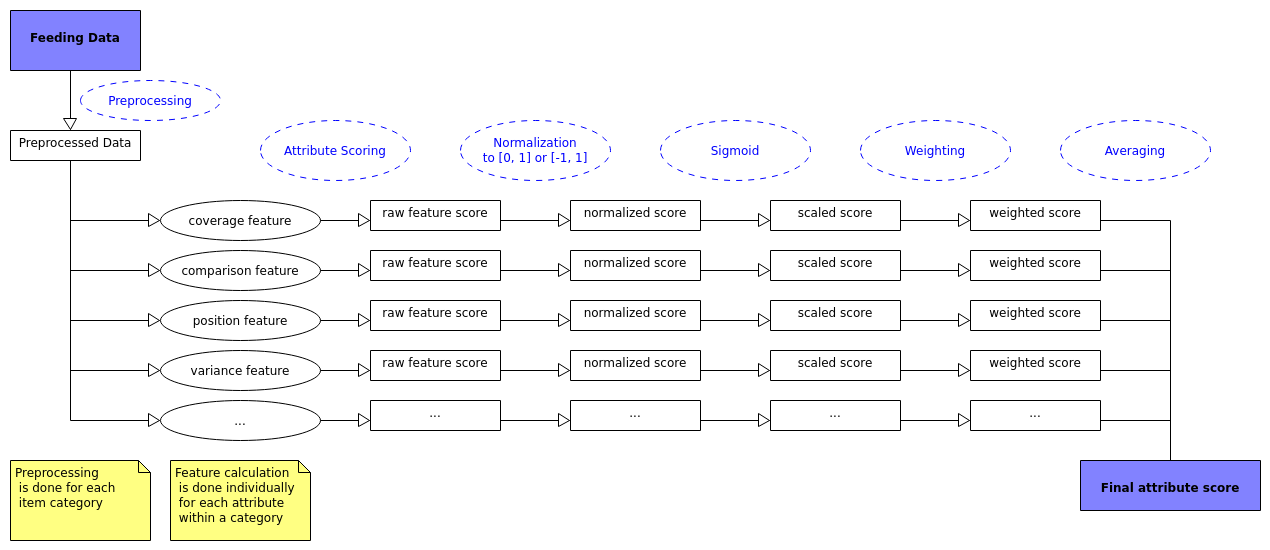
With facet generation it is possible to find the most meaningful attributes within each item category, based on statistical analysis of your feeding data. The process scores each attribute used in your data, by analyzing features such as the average position of the attribute, or the coverage of the attribute amongst all items in the category (see Configuring features JSON for all available features).
Usage
Requirements
- You need to have a QSC feeding API prepared, to which data was already fed
- Your fed data needs to have used the category and attribute format described in the Feeding API Integration documentation
- We can create a custom converter for your data, if it is not in the required format
- You need to have a QSC Admin config prepared, into which the generated facets will be written
- To represent different sets of facets for different states of your feeding data, you can use different resulting configs
- Your feeding items need to have an id element. This element can be:
- A unique string
- Or a list of unique strings, from which the first one will be used as identifier
- Or any other element.
- In this case the process identifies the feeding items by an internal counter and thus includes duplicate items
- Your feeding items need to have a category element. This element can be:
- A unique string
- A list of unique strings, from which every string is used. The feeding item is considered on scoring attributes of all categories it is part of.
- A category traverse element with the structure described in QSC Admin Feeding API Doc
- In this case only leaf categories (with the highest level) of the traverse are considered
Configuration
Standard Run
When using default settings, you have to choose the feeding API for which you want to generate facets for, and the results config in which the resulting facets should be stored.
Notice that you might have to change your item id and categories id element identifier if you aren't using "id" and "categories" as identifiers in your feeding items
TODO: how to select feeding API and results config in QSC UI
Custom Run
To configure the facet generation yourself, you have to create a new config in QSC Admin: How to use configs in QSC Admin.
The config is a JSON which must contain at least
"config-api-results-url": The url of the config in which the generated facets should be stored"config-api-results-token": A token to access the config in which the generated facets should be stored"config-api-results-code": The code of the config in which the generated facets should be stored- Note that this code also overwrites the name of the config on uploading on the results, if code and name were not equal before
"config-api-results-tenant-code": Your tenant code"feeding-api-url": The feeding API for which items you want to generate facets for"feeding-api-token": A token to access the items of your feeding API
e.g.
{
"config-api-results-url": "https://qsc.quasiris.de/api/v1/admin/config/my-tenant/generated-facets",
"config-api-results-token": "my-generated-config-token-1234567890abcdef",
"config-api-results-code": "generated-facets",
"config-api-results-tenant-code": "my-tenant",
"feeding-api-url": "https://qsc.quasiris.de/api/v1/feeding/my-tenant/my-feeding/_data-full",
"feeding-api-token": "my-generated-feeding-api-token-1234567890abcdef"
[...]
}
For all other available configuration options see Configuration Options
TODO how to select custom config in QSC UI
Generate Facets
TODO Where to start the process
Get Result
You can find the results of your facet generation run at your specified results config, e.g.:
https://qsc.quasiris.de/admin/#/config/my-tenant/generated facets
An example of the resulting JSON:
{
"category-identifier-12345": {
"scores": [
{
"attribute": "id-123-456-789",
"score": 0.42529928693018315
},
{
"attribute": "weight",
"score": 0.4216055372330198
},
{
"attribute": "color",
"score": 0.4122466859450757
},
[...]
]
},
...
}
Configuration Options
The following config JSON options are available:
Required Settings
| Config JSON element name | Default Value | Description |
|---|---|---|
config-api-results-url | None | QSC Admin Config API URL to which the results are uploaded |
config-api-results-token | None | X-QSC-Token as authentication for uploading results as a config to QSC Admin API |
config-api-results-code | None | QSC Admin config code of your results config, used for writing the resulting generated configs into a QSC Admin config |
config-api-results-tenant-code | None | QSC Admin tenant code, used to identify you for the usage of QSC APIs available to you |
feeding-api-url | None | QSC Admin Feeding API URL, used to gather your feeding data for scoring the available attributes as facets |
feeding-api-token | None | X-QSC-Token as authentication for reading data from feeding API |
TODO: make tenant code fixed by UI, so customers don't have to enter tenant codes, and cannot enter a wrong code by accident
Optional Settings
| Config JSON element name | Default Value | Description |
|---|---|---|
config-api-settings-url | None | Config API URL from which a QSC Admin config can be loaded to receive the settings for your run |
config-api-settings-token | None | X-QSC-Token as authentication for reading the settings from QSC Admin API |
feeding-api-page-size | 1000 | Page size of the feeding API requests |
feeding-api-sleep-time | 1.0 | Time between feeding API requests in seconds, used to reduce server load |
feeding-api-product-id-element | id | JSON element of the product that identifies the (list of) product id(s) |
feeding-api-category-id-element | categories | JSON element of the product that identifies the (list of) category id(s). Categories can also be in the QSC format described on QSC Admin Docs |
scoring_ignore_attribute_tag | "ignore" | attributes that contain a 'tags' list which contains this tag are ignored for scoring |
scoring-min-products-in-category | 10 | Minimum amount of products a category needs to be considered in scoring |
scoring-top-n-attributes | 10 | Amount of top attributes per category in top output file |
scoring-features-json | Combination of basic features that were useful in customer scenarios | json containing feature settings |
Configuring features JSON
If you want to use your own set of features to get the most fitting attributes, you have to define them within a JSON string. Each feature can be used once and all features can be individually combined.
Feature JSON structure
"scoring-features-json":
{
[feature-name]:
{
"linear-interval": "-11",
"sigmoid-curvature": 0.35,
"weight": 0.4
},
[...]
}
Available features
You can choose between multiple features or use a combination of them in order to fine tune your facet selection. The default setting uses all available features that are solely based on attributes, with settings that were useful in customer scenarios.
| Feature Name | Description |
|---|---|
coverage | In how many percent of the categories products is the attribute used |
comparison | Difference in coverage of an attribute between all categories and the current category. A negative score means, the attribute is used less often in this category than in general. A positive score means the attribute is used more often in this category than in general. |
position | The distance between maximum attribute position and the average position of the current attribute inside the same category. Higher scores indicate that an attribute is at a leading position. |
variance | The amount of variance in the value distribution for each attribute. If you have an evenly distributed usage of possible attribute values, the variance is low. If some attribute values are used very often and some very seldom, the variance is high. If you prefer lower variance, weight this feature negatively! |
Required values for each feature
Each feature has to be configures on an interval, a sigmoid curvature and a weight that is used to weight each feature into the overall score for each attribute.
| Value | Type | Description |
|---|---|---|
linear-interval | either "01" or "-11" | Determines to which interval scores of this feature are normalized to. Either interval [0, 1] or [-1, 1] is used. |
sigmoid-curvature | float value in [-1, 1] | Determines a curvature used for scaling the normalized scores of this feature in a nonlinear way via a sigmoid function. See this external interactive sigmoid graph for a demo of how scores are scaled by the curvature value |
weight | float value | Determines the multiplier with which the normalized and scaled scores of this feature are weighted. When using weight values from [0, 1], you will only get scores in [-1, 1] which you can treat similar to confidence scores. |
Pipeline Overview
To better understand the sequence of feature calculation, normalization, scaling and weighting for configuring the required values, you can take a look at the process diagram: